
merge和concat都可以把多个流合并成一个流,不同的是merge会同时订阅所有接收到的流,而concat是按顺序一个一个的订阅。
例如我们有三个流a1,a2和a3
merge会同时订阅这三个流,并将接收到的数据在不保证顺序的情况下发布给订阅者。concat会先订阅a1,将a1的数据按照接收顺序发布给订阅者。当a1数据发布结束后订阅a2,当a2数据发布结束后再订阅a3。- Project Reactor - flatMapSequential的工作原理中的
mergeSequential会和merge一样同时订阅这三个流,但它会先发布a1的数据,再发布a2的数据,最后发布a3的数据。这就要求每个流都有一个数据缓存,而不像concat只需要一个数据缓存。
下面我们来介绍这两个方法的工作原理。
merge
使用方法
这里我们以Flux.merge为例, 它的使用方法如下
场景1:合并一个流中的所有流
Flux.merge(Flux.just(Flux.just(1,1), Flux.just(2,2))).blockFirst(); //1,1,2,2
它等价于
Flux.just(Flux.just(1,1), Flux.just(2,2)).flatMap(x -> x).blockFirst(); //1,1,2,2
而在代码实现上,它也复用了Project Reactor - flatMap的工作原理。
场景2:合并一个数组中的所有流
Flux.merge(Flux.just(1,1), Flux.just(2,2)).blockFirst(); //1,1,2,2
和场景1不同的是,该场景直接以Vargs接收多个Publisher,它们在函数中以数组形式存在。
工作原理
这里我们只讨论场景2的工作原理,Project Reactor引入了FluxMerge对这种场景做了优化,它省去了flatMap中 FluxFlatMap的订阅操作,直接用FluxMapMain订阅FluxArray.ArraySubscription
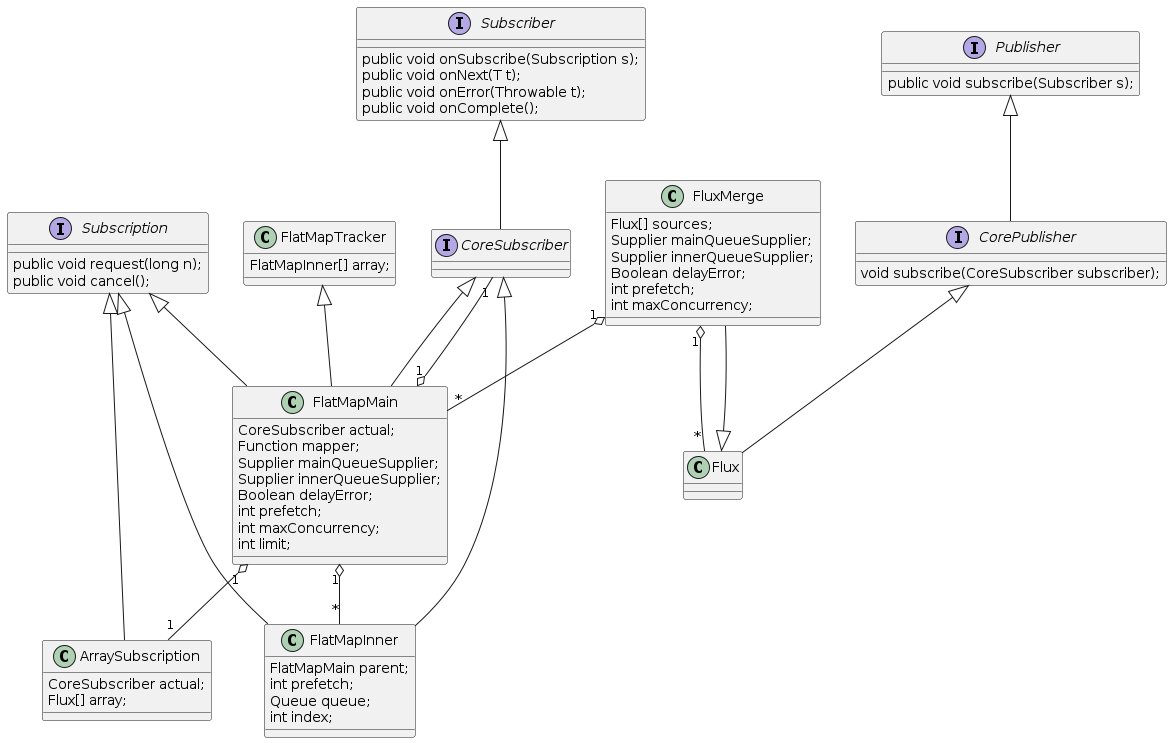
以场景2的代码为例,其工作流程如下
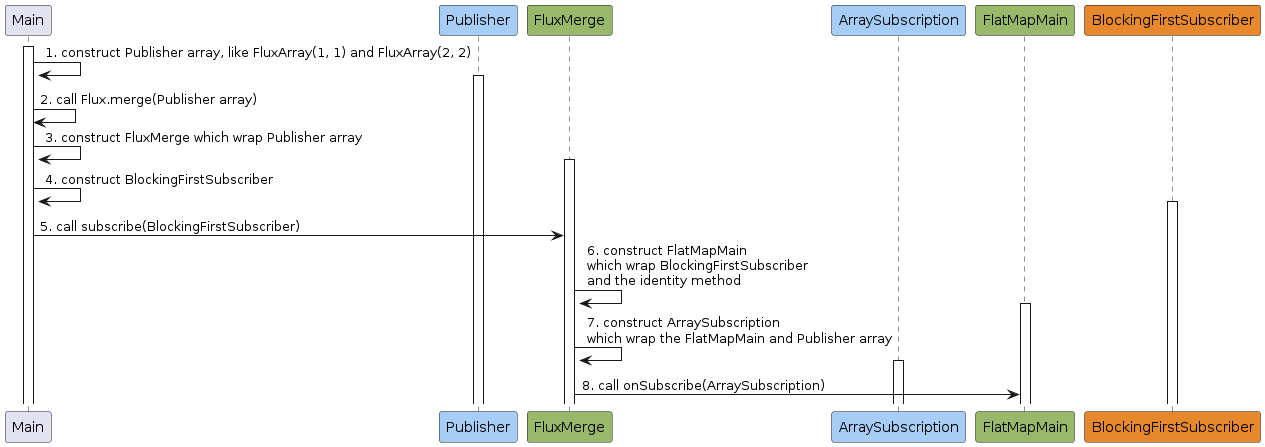
这里FluxMerge和FluxFlatMap不同的是,它没有订阅Publihser数组,而是直接构建了ArraySubscription来通知FlatMapMain订阅成功。我在这里只列出了前9步,后续步骤和flatMap一致,就不再赘述。
- 主程序创建
Publisher数组,它的每一个元素都是一个CorePublisher。 - 主程序调用
Flux.merge对Publisher数组中的CorePublisher进行合并。 - 主程序创建
FluxMerge实例,它包含了Publisher数组,并且也是一个CorePublisher。 - 主程序创建
BlockingFirstSubscriber实例。 - 主程序调用
FluxMerge.subscribe(BlockingFirstSubscriber)订阅FluxMerge。 FluxMerge创建FlatMapMain实例,它包含了BlockingFirstSubscriber和转换函数f, 这里f是identity函数,该函数会原样返回输入值。FluxMerge创建ArraySubscription实例,它包含了FlatMapMain和Publisher数组。FluxMerge调用FlatMapMain.onSubscribe(ArraySubscription)来通知FlatMapMain订阅成功。注意,这里FlatMapMain并不需要发起订阅请求。
concat
这里我们以Flux.concat为例,它有三种不同的实现方式,对应三种使用场景。
场景1:合并一个数组中的所有流
使用方法
Flux.concat(Flux.just(1,1), Flux.just(2,2)).blockFirst(); //1,1,2,2
这里concat以Vargs接收多个Publisher, 而Vargs在函数内部以数组的形式存在。
工作原理
为了充分利用数组长度固定,易于遍历的特点,Project Reactor引入了FluxConcatArray和ConcatArraySubscriber来支持该场景。其类图如下
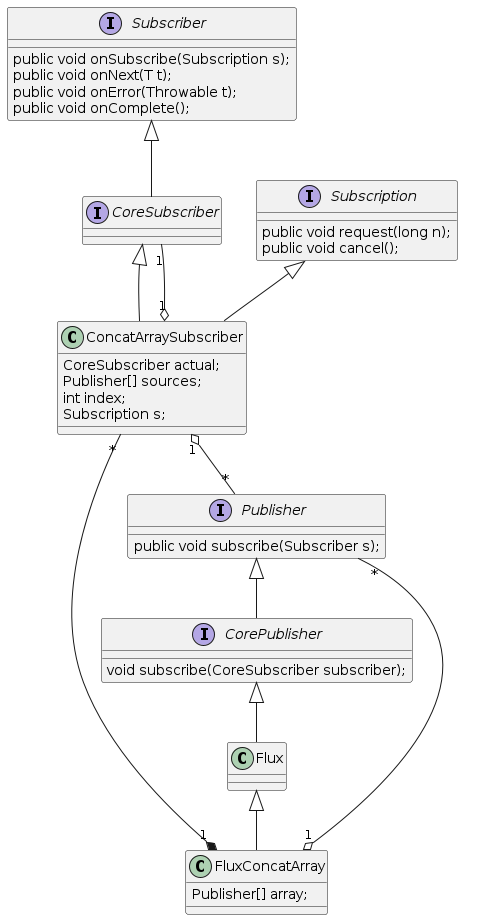
以上述代码为例,其工作流程如下
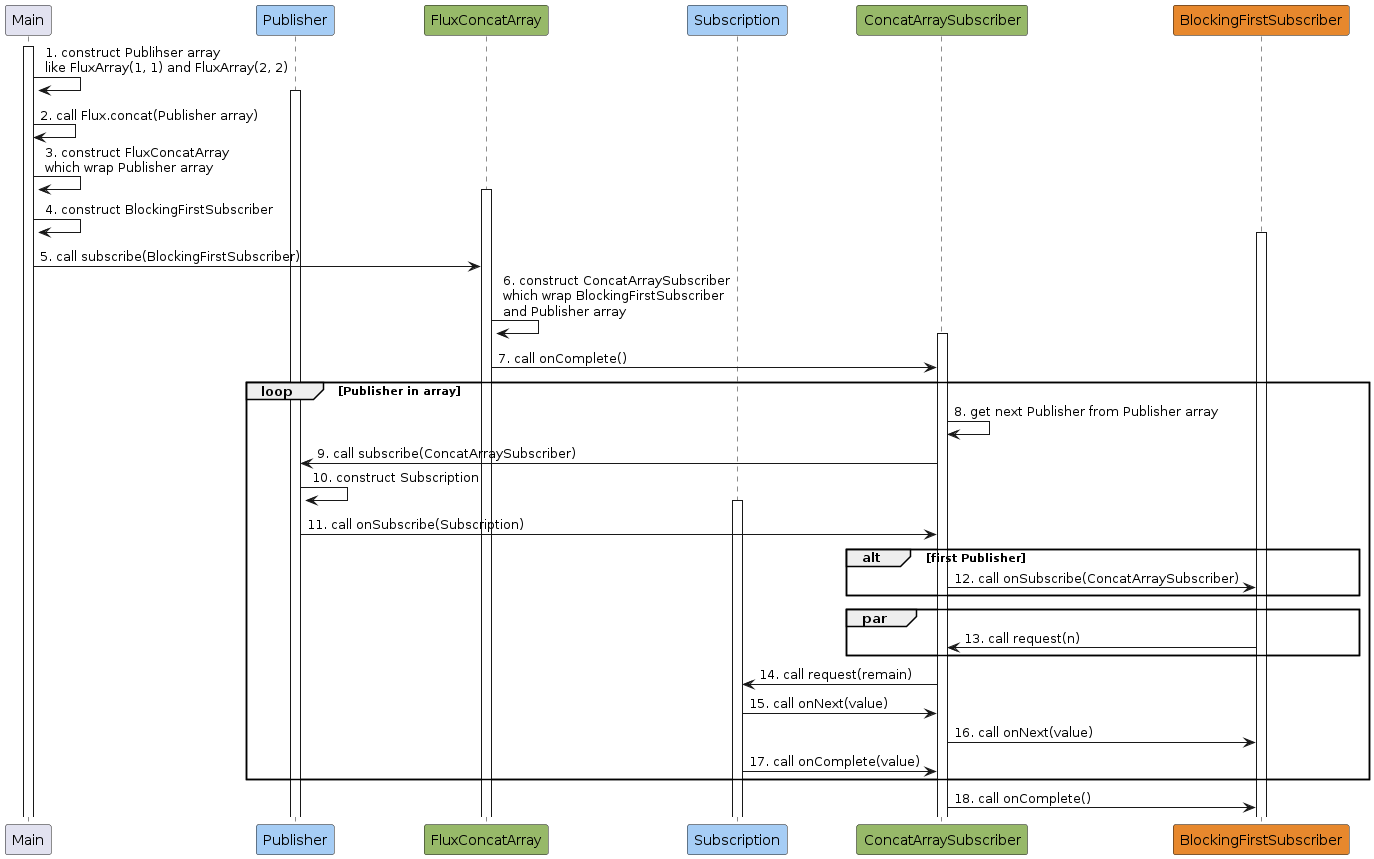
- 主程序创建
Publisher数组,它的每一个元素都是一个CorePublisher。 - 主程序调用
Flux.concat(Publisher array)对Publisher数组中的CorePublisher进行合并。 Flux.concat创建FluxConcatArray实例,它包含了Publisher数组。- 主程序创建
BlockingFirstSubscriber实例。 - 主程序调用
FluxConcatArray.subscribe(BlockingFirstSubscriber)订阅FluxConcatArray。 FluxConcatArray创建ConcatArraySubscriber实例,它包含了BlockingFirstSubscriber和Publisher数组。FluxConcatArray调用ConcatArraySubscriber.onComplete()来通知ConcatArraySubscriber数据发布结束。大家可能注意到,这里ConcatArraySubscriber并未请求任何数据却直接收到了onComplete。这样做的原因是ConcatArraySubscriber已经拿到了Publisher数组,不需要再像flatMap中的FlatMapMain那样等待数据发布。ConcatArraySubscriber从Publisher数组中获取一个Publihser。ConcatArraySubscriber调用Publisher.subscribe(ConcatArraySubscriber)来订阅该Publisher。Publisher创建Subscription实例。Publisher调用ConcatArraySubscriber.onSubscribe(Subscription)来通知ConcatArraySubscriber订阅成功。- 如果该
Publisher是数组中的第一个Publisher,ConcatArraySubscriber调用BlockingFirstSubscriber.onSubscribe(ConcatArraySubscriber)来通知其订阅成功。 BlockingFirstSubscriber调用ConcatArraySubscriber.request(n)来请求固定大小的数据,该调用可发生多次且可在第12步后任何时间点发生。ConcatArraySubscriber调用Subscription.request(remain)来请求数据,其大小为BlockingFirstSubscriber请求大小减去已发布数据大小。Subscription调用ConcatArraySubscriber.onNext(value)来向ConcatArraySubscriber发布数据,该调用可发生多次。ConcatArraySubscriber调用BlockingFirstSubscriber.onNext(value)来向BlockingFirstSubscriber发布数据。- 在数据发布结束时,
Subscription调用ConcatArraySubscriber.onComplete()来通知ConcatArraySubscriber数据发布结束。回到步骤8,直到ConcatArraySubscriber的Publisher数组遍历完成。 - 如果
Publihser数组遍历完成且Subscription数据发布结束,调用BlockingFirstSubscriber.onComplete()来通知BlockingFirstSubscriber数据发布结束。
场景2:合并一个可迭代对象中的所有流
使用方法
import io.vavr.collection.List
Flux.concat(List.of(Flux.just(1,1), Flux.just(2,2))).blockFirst(); //1,1,2,2
这里我们使用了Vavr的List,它是一个Iterable。
工作原理
Iterable的遍历和数组不同,Project Reactor 引入了FluxConcatIterable和ConcatIterableSubscriber来支持该场景。其类图如下
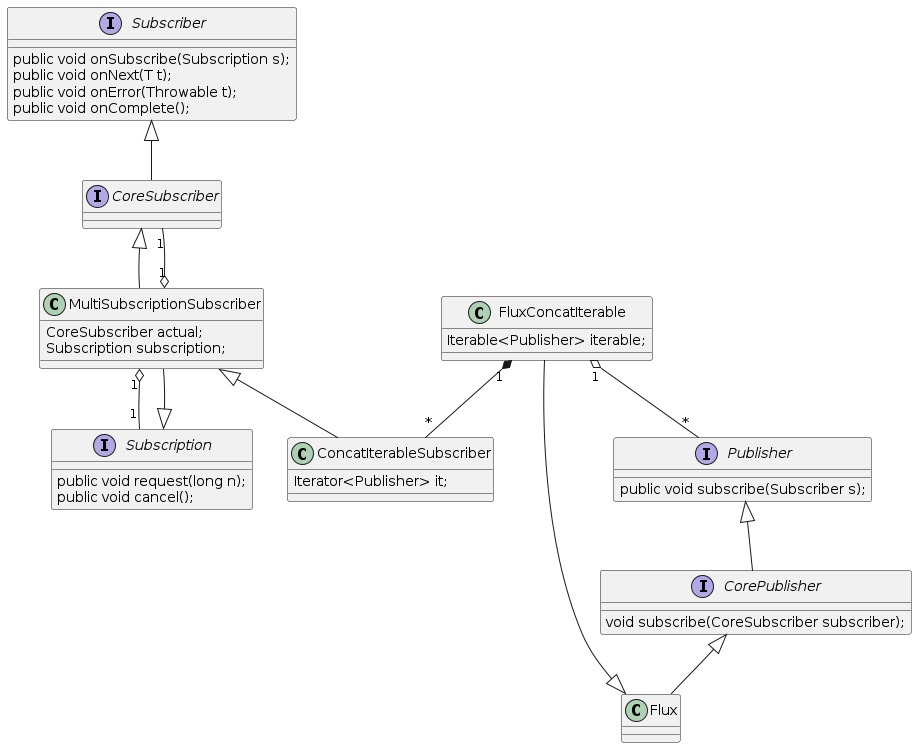
以上述代码为例,其工作流程如下
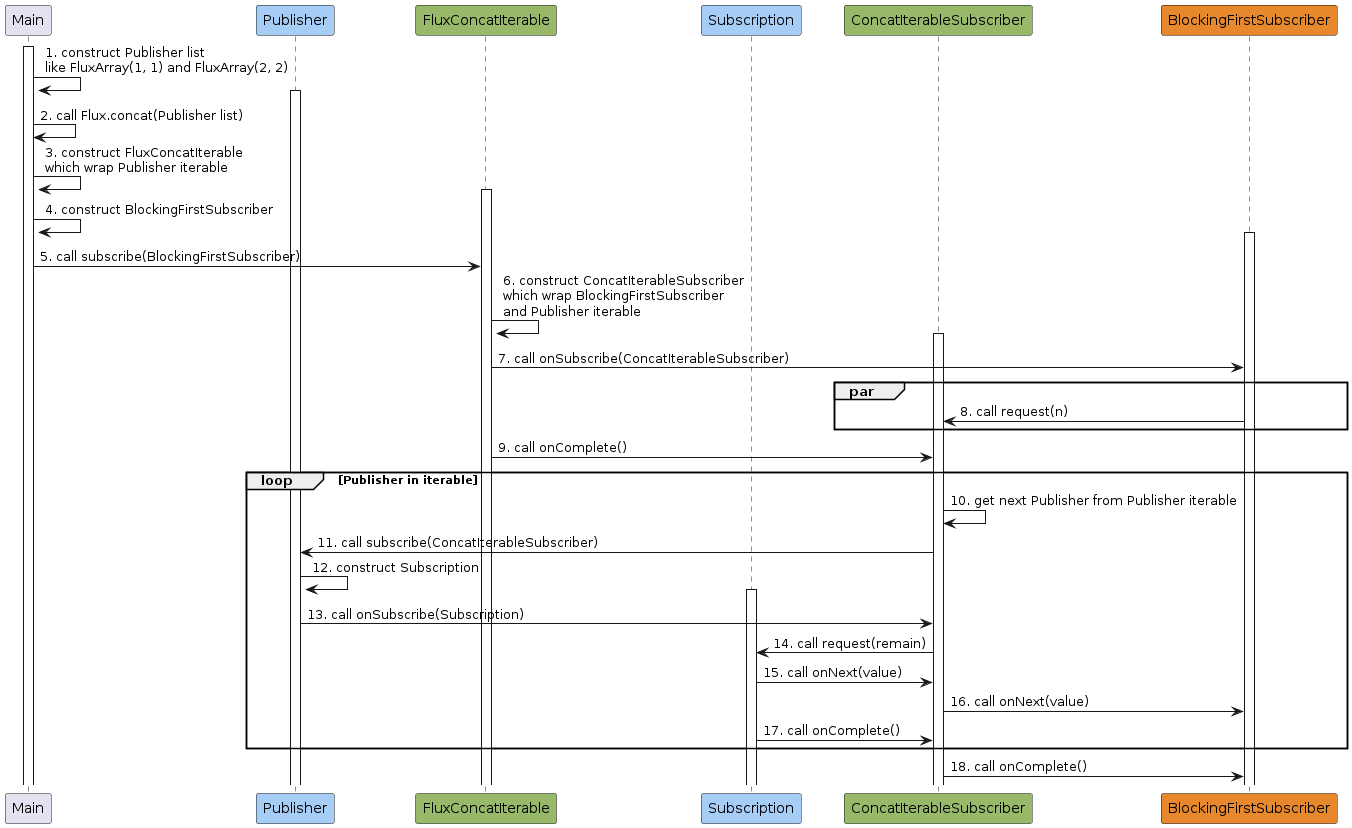
- 主程序创建
Publisher列表,它的每一个元素都是一个CorePublisher。 - 主程序调用
Flux.concat(Publisher list)对Publisher列表中的CorePublisher进行合并。 Flux.concat创建FluxConcatIterable示例,它包含了Publisher列表。- 主程序创建
BlockingFirstSubscriber实例。 - 主程序调用
FluxConcatIterable.subscribe(BlockingFirstSubscriber)订阅FluxConcatIterable。 FluxConcatIterable创建ConcatIterableSubscriber实例,它包含了BlockingFirstSubscriber和Publisher列表。FluxConcatIterable调用BlockingFirstSubscriber.onSubscribe(ConcatIterableSubscriber)来通知其订阅成功。BlockingFirstSubscriber调用ConcatIterableSubscriber.request(n)来请求固定大小的数据,该调用可发生多次且可在第7步后任何时间点发生。FluxConcatIterable调用ConcatIterableSubscriber.onComplete()来通知ConcatIterableSubscriber数据发布结束。大家可能注意到,这里ConcatIterableSubscriber并未请求任何数据却直接收到了onComplete。这样做的原因是ConcatIterableSubscriber已经拿到了Publisher列表,不需要再像flatMap中的FlatMapMain那样等待数据发布。ConcatIterableSubscriber从Publisher列表中获取一个Publihser。ConcatIterableSubscriber调用Publisher.subscribe(ConcatIterableSubscriber)来订阅该Publisher。Publisher创建Subscription实例。Publisher调用ConcatIterableSubscriber.onSubscribe(Subscription)来通知ConcatIterableSubscriber订阅成功。ConcatIterableSubscriber调用Subscription.request(remain)来请求数据,其大小为BlockingFirstSubscriber请求大小减去已发布数据大小。Subscription调用ConcatIterableSubscriber.onNext(value)来向ConcatIterableSubscriber发布数据,该调用可发生多次。ConcatIterableSubscriber调用BlockingFirstSubscriber.onNext(value)来向BlockingFirstSubscriber发布数据。- 在数据发布结束时,
Subscription调用ConcatIterableSubscriber.onComplete()来通知ConcatIterableSubscriber数据发布结束。回到步骤10,直到ConcatIterableSubscriber的Publisher列表遍历完成。 - 如果
Publihser列表遍历完成且Subscription数据发布结束,调用BlockingFirstSubscriber.onComplete()来通知BlockingFirstSubscriber数据发布结束。
场景3:合并一个流中的所有流
使用方法
Flux.concat(Flux.just(Flux.just(1,1), Flux.just(2,2))).blockFirst(); //1,1,2,2
这里concat接收的是一个流,它的每一个元素都是我们想要合并的流。它是concatMap的一个特殊实现,上面的代码等价于
Flux.just(Flux.just(1,1), Flux.just(2,2)).concatMap(x -> x).blockFirst(); //1,1,2,2
工作原理
这里我们直接讲解concatMap的实现原理,其类图如下
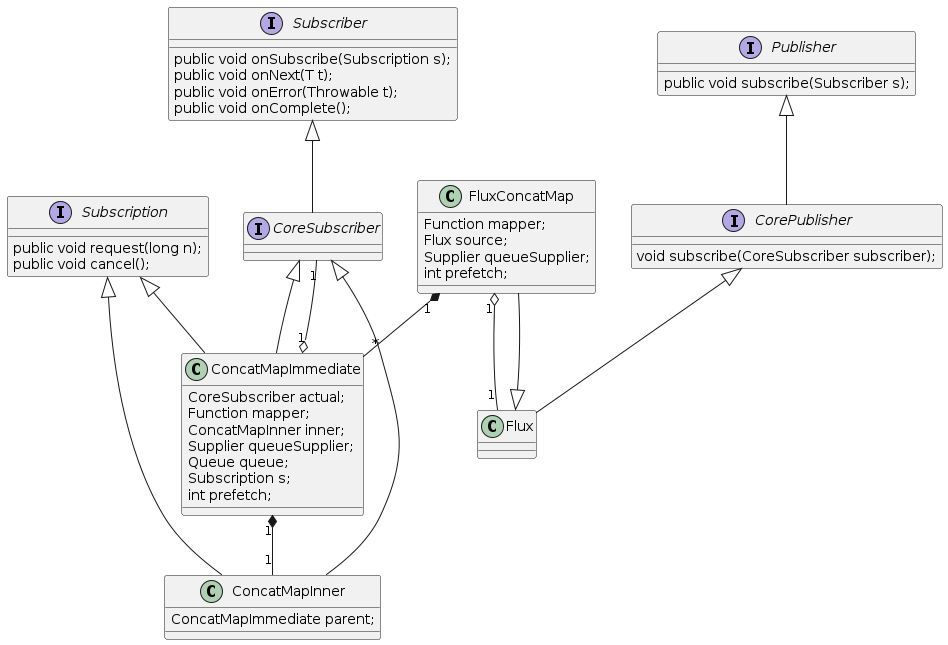
以上面的代码为例,其工作流程如下
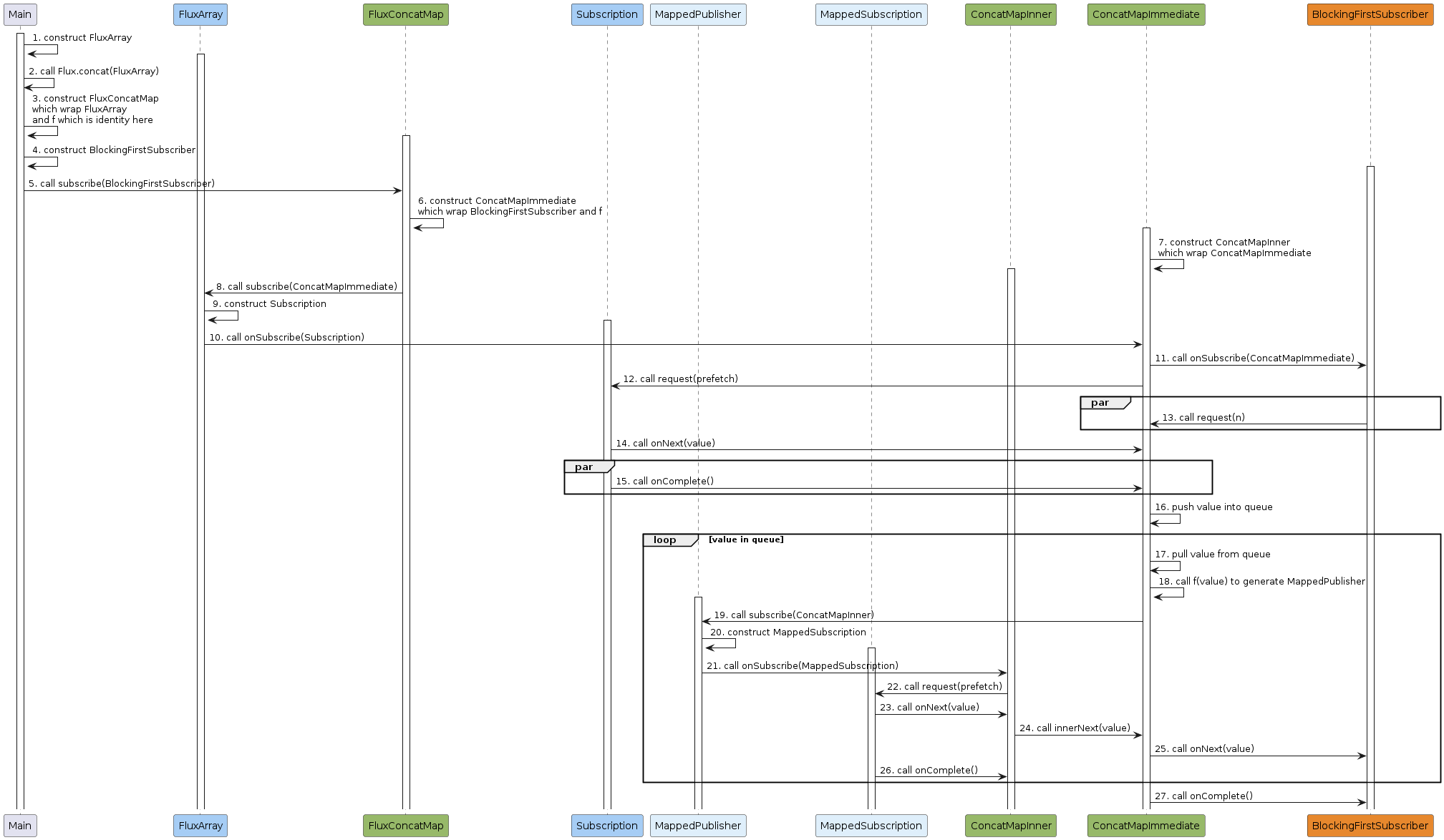
- 主程序创建
FluxArray实例,它的每一个元素都是一个CorePublisher。 - 主程序调用
Flux.concat(FluxArray)对FluxArray中的CorePublisher进行合并。 Flux.concat创建FluxConcatMap示例,它包含了FluxArray和一个转换函数f,在上述代码中,f是identity函数。- 主程序创建
BlockingFirstSubscriber实例。 - 主程序调用
FluxConcatMap.subscribe(BlockingFirstSubscriber)订阅FluxConcatMap。 FluxConcatMap创建ConcatMapImmediate实例,它包含了BlockingFirstSubscriber和f。ConcatMapImmediate创建ConcatMapInner实例,它用来订阅FluxArray中的每一个CorePublisher。FluxConcatMap调用FluxArray.subscribe(ConcatMapImmediate)订阅FluxArray。FluxArray创建Subscription实例。FluxArray调用ConcatMapImmediate.onSubscribe(Subscription)来通知ConcatMapImmediate订阅成功。ConcatMapImmediate调用BlockingFirstSubscriber.onSubscribe(ConcatMapImmediate)来通知BlockingFirstSubscriber订阅成功,这里ConcatMapImmediate既是一个Subscriber,也是一个Subscription。ConcatMapImmediate调用Subscription.request(prefetch)来请求数据,其大小为数据预加载大小。该调用采取预加载的模式,接收的数据会先存储到ConcatMapImmediate的数据队列中, 不需要等待BlockingFirstSubscriber调用ConcatMapImmediate.request(n)。BlockingFirstSubscriber调用ConcatMapImmediate.request(n)来请求固定大小的数据,该调用可发生多次且可在步骤11后的任意时间发生。Subscription调用ConcatMapImmediate.onNext(value)来向ConcatMapImmediate发布数据,该调用可发生多次。- 在数据发布结束时,
Subscription需要调用ConcatMapImmediate.onComplete()来通知ConcatMapImmediate数据发布结束。该步骤可以发生在第11步之后的任何时间点,和后续步骤是并行关系 ConcatMapImmediate将接收到的数据放入数据队列。ConcatMapImmediate从数据队列中获取一个元素,ConcatMapImmediate调用f(value)来对数据进行转换,在上述代码中转换后的数据还是value, 它是一个Publisher,这里我们将其命名为MappedPublisher。ConcatMapImmediate调用MappedPublisher.subscribe(ConcatMapInner),注意这里不会生成新的ConcatMapInner实例,而是复用同一个实例。MappedPublisher创建Subscription实例,这里我们将其命名为MappedSubscription。MappedPublisher调用ConcatMapInner.onSubscribe(MappedSubscription)来通知ConcatMapInner订阅成功。ConcatMapInner调用MappedSubscription.request(remain)来请求数据,其大小为BlockingFirstSubscriber请求大小减去已发布数据大小。MappedSubscription调用ConcatMapInner.onNext(value)来向ConcatMapInner发布数据,该调用可发生多次。ConcatMapInner调用ConcatMapImmediate.innerNext(value)来向ConcatMapImmediate发布数据。ConcatMapImmediate调用BlockingFirstSubscriber.onNext(value)来向BlockingFirstSubscriber发布数据。- 在数据发布结束时,
MappedSubscription调用ConcatMapInner.onComplete()来通知ConcatMapInner数据发布结束。回到步骤17,直到ConcatMapImmediate数据队列为空。 - 如果数据队列为空且
Subscription数据发布结束,调用BlockingFirstSubscriber.onComplete()来通知BlockingFirstSubscriber数据发布结束。
不同时间点的状态变化
以场景3为例,我们看一下Flux.concat在不同时间点的状态变化。

这里我们假设Subscription发布了三个元素,每个元素都会生成一个MappedSubscription。
- 状态1
ConcatMapImmediate从数据队列中获取第一个元素,并生成对应的MappedSubscription。ConcatMapInner订阅该MappedSubscription并向Subscriber转发数据,直到数据发布结束。ConcatMapImmediate将第二个元素存储到它的数据队列中。ConcatMapImmediate将第三个元素存储到它的数据队列中。
- 状态2
- 第一个
MappedSubscription数据发布结束。 ConcatMapImmediate从数据队列中获取第二个元素,并生成对应的MappedSubscription。ConcatMapInner订阅该MappedSubscription并向Subscriber转发数据,直到数据发布结束。ConcatMapImmediate将第三个元素存储到它的数据队列中。
- 第一个
- 状态3
- 第一个
MappedSubscription数据发布结束。 - 第二个
MappedSubscription数据发布结束。 ConcatMapImmediate从数据队列中获取第三个元素,并生成对应的MappedSubscription。ConcatMapInner订阅该MappedSubscription并向Subscriber转发数据,直到数据发布结束。
- 第一个
总结
merge和concat没有看起来那么简单,它们针对不同的数据源有不同的实现。下一篇我们讲解reduce,看看它和concat一起使用会有什么效果。

