
reduce可以将流中的元素按一定规则进行合并,例如求和,求积等。它的返回类型是Mono而不是Flux。它需要我们提供两个信息
1. 初始值,可选,默认值为流中的第一个元素
2. 合并规则,用于计算当前合并结果与流中下个元素合并后的合并结果。它是一个函数BiFunction<A, ? super T, A>,其中A是合并后的数据类型,T为流中元素的数据类型。
使用方法
这里我们以Flux.reduce为例, 它的使用方法如下
无初始值
Flux.just(1, 2, 3, 4).reduce((x, y) -> x + y).block(); // 10
有初始值
Flux.just(1, 2, 3, 4).reduce(10, (x, y) -> x + y).block(); // 20
Flux.just(1, 2, 3, 4).reduceWith(() -> 10, (x, y) -> x + y).block(); // 20
这里reduce(10, (x, y) -> x + y)内部调用了reduce(() -> 10, (x, y) -> x + y)。
工作原理
虽然无初始值和有初始值的场景差别不大,但Project Reactor使用了两种不同的实现。
无初始值
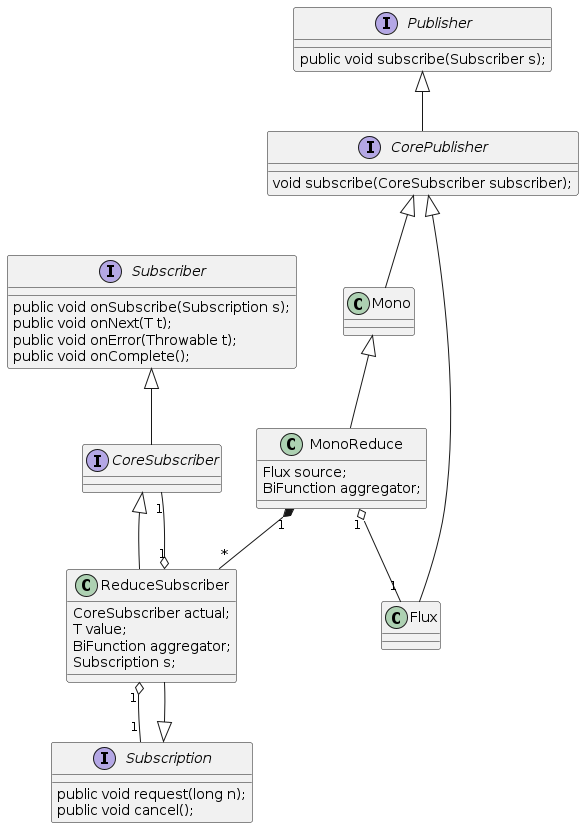
以上面的代码为例,无初始值的reduce的工作流程如下
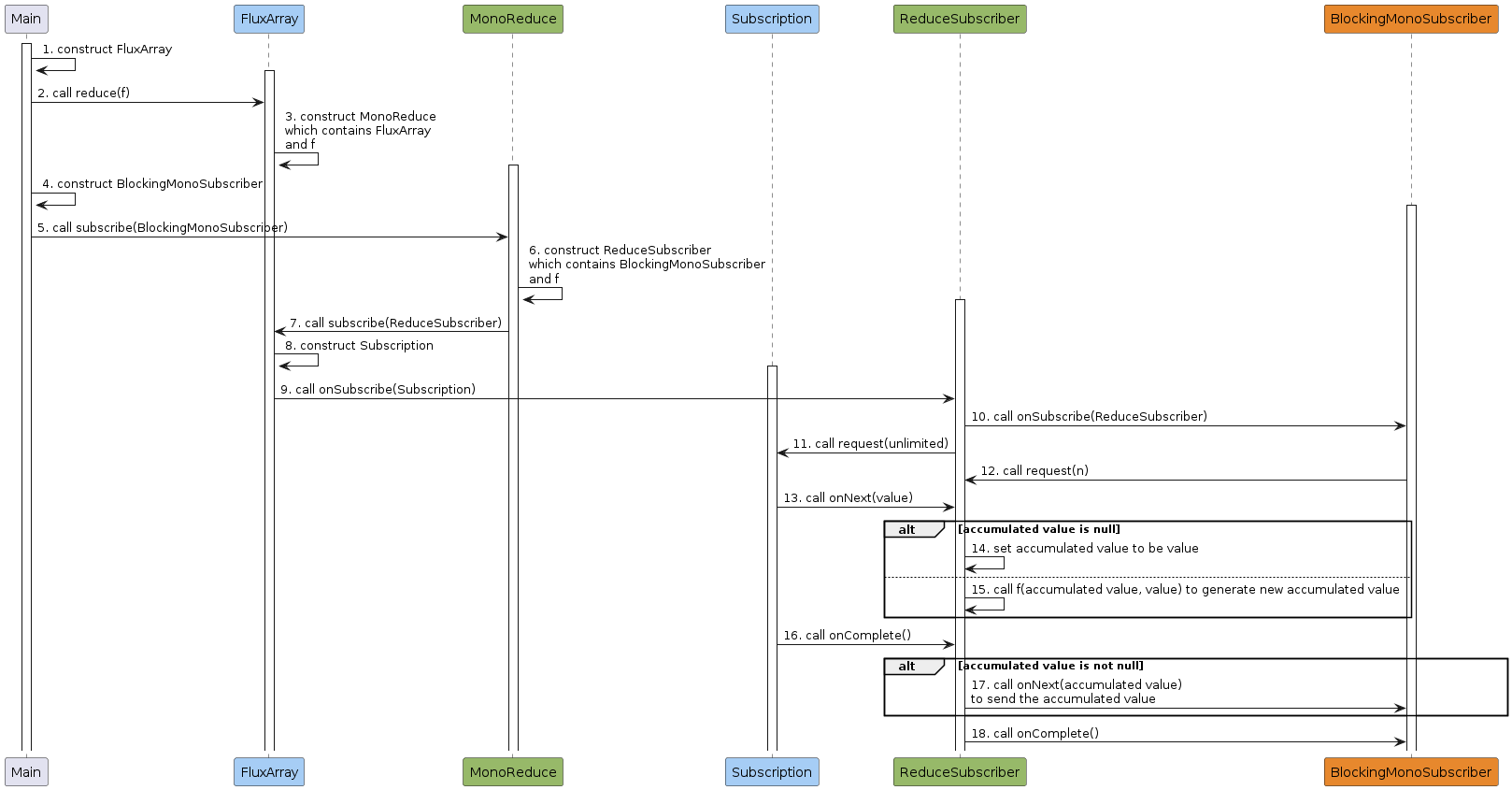
- 主程序创建
FluxArray实例,它是一个CorePublisher。 - 主程序调用
FluxArray.reduce(f)对数据进行累计操作。 FluxArray创建MonoReduce实例,它包含了FluxArray和f,并且也是一个CorePublisher。- 主程序创建
BlockingMonoSubscriber实例。 - 主程序调用
MonoReduce.subscribe(BlockingMonoSubscriber)订阅MonoReduce。 MonoReduce创建ReduceSubscriber实例,它包含了BlockingMonoSubscriber和f。MonoReduce调用FluxArray.subscribe(ReduceSubscriber)订阅FluxArray。FluxArray创建Subscription实例。FluxArray调用ReduceSubscriber.onSubscribe(Subscription)来通知ReduceSubscriber订阅成功。ReduceSubscriber调用BlockingMonoSubscriber.onSubscribe(ReduceSubscriber)来通知BlockingMonoSubscriber订阅成功,这里ReduceSubscriber既是一个Subscriber,也是一个Subscription。ReduceSubscriber调用Subscription.request(unlimited)来请求数据,其大小为Long.MAX_VALUE,也就是无数量限制。BlockingMonoSubscriber调用ReduceSubscriber.request(n)来请求固定大小的数据,该调用可发生多次。Subscription调用ReduceSubscriber.onNext(value)来向ReduceSubscriber发布数据,该调用可发生多次。- 当累计结果不存在时,将
value设置为累计结果。 - 当累计结果存在时,
ReduceSubscriber调用f(acuumulated value, value)来对计算新的累计结果。 - 在数据发布结束时,
Subscription需要调用ReduceSubscriber.onComplete()来通知ReduceSubscriber数据发布结束。 - 当累积结果存在时,
ReduceSubscriber调用BlockingMonoSubscriber.onNext(accumulated value)来向BlockingMonoSubscriber发布累计数据。 ReduceSubscriber调用BlockingMonoSubscriber.onComplete()来通知BlockingMonoSubscriber数据发布结束。
有初始值
和无初始值场景使用MonoReduce和ReduceSubscriber不同,有初始值场景使用MonoReduceSeed和ReduceSeedSubscriber来实现。
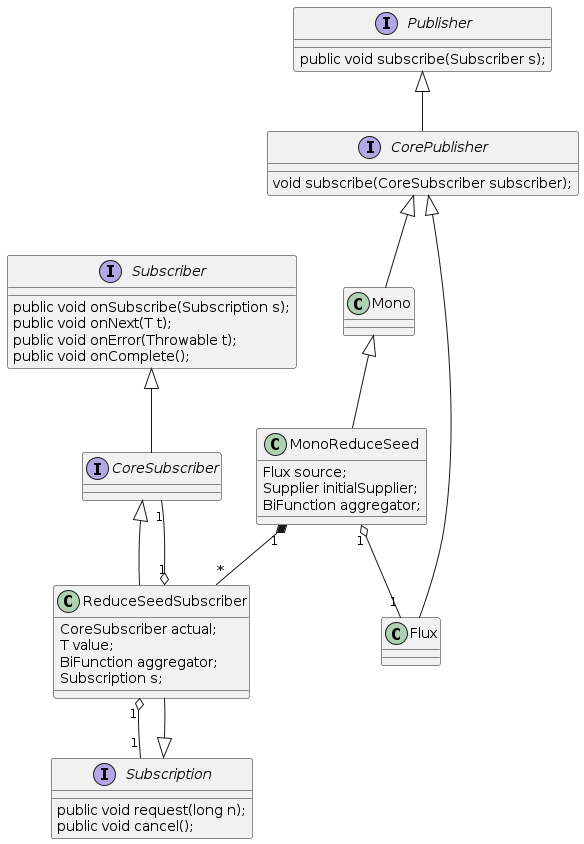
以上面的代码为例,有初始值的reduce的工作流程如下
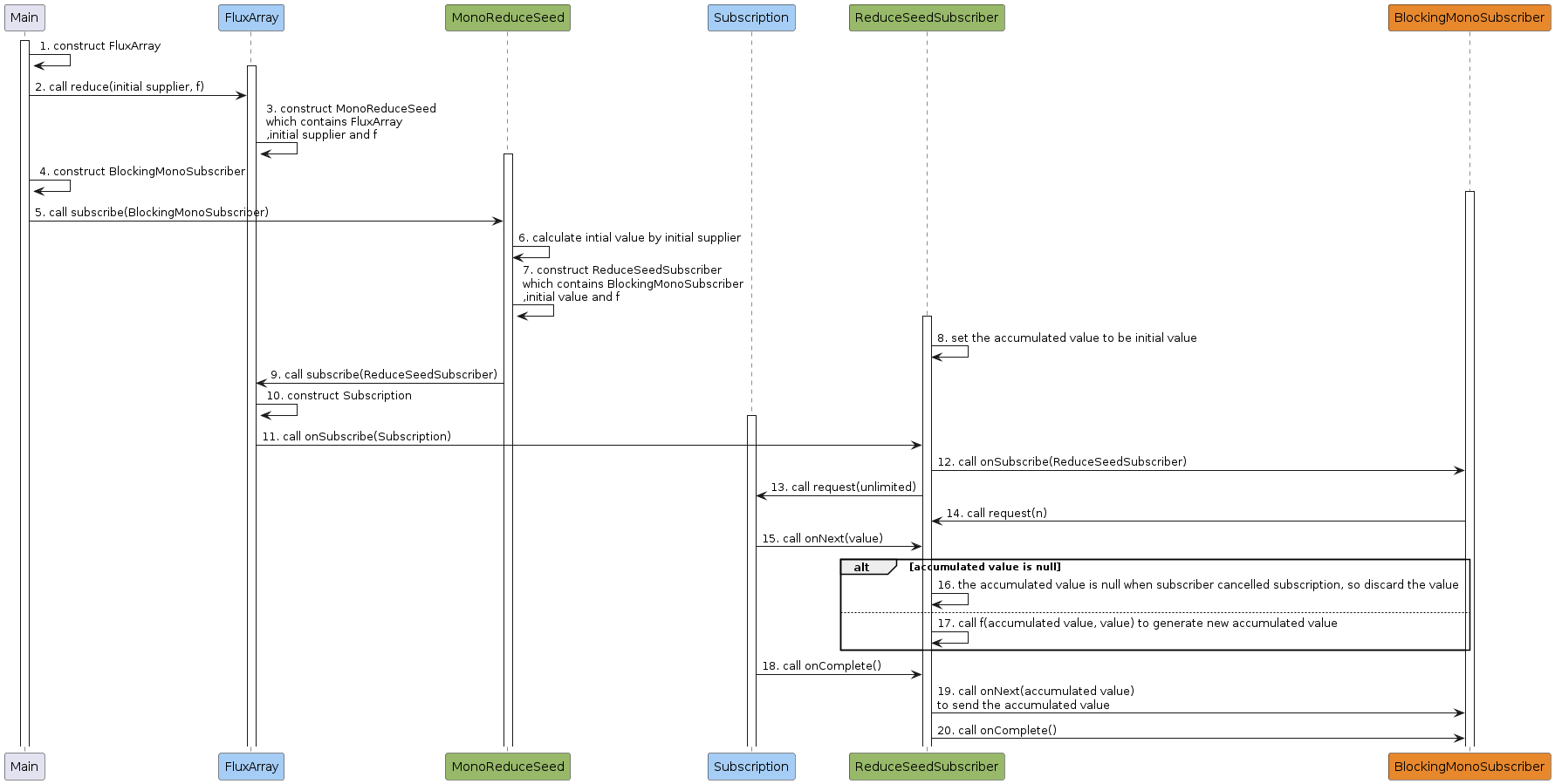
- 主程序创建
FluxArray实例,它是一个CorePublisher。 - 主程序调用
FluxArray.reduce(initial supplier, f)对数据进行累计操作。 FluxArray创建MonoReduceSeed实例,它包含了FluxArray,iniital supplier和f,并且也是一个CorePublisher。- 主程序创建
BlockingMonoSubscriber实例。 - 主程序调用
MonoReduceSeed.subscribe(BlockingMonoSubscriber)订阅MonoReduceSeed。 MonoReduceSeed通过initial supplier计算初始值。MonoReduceSeed创建ReduceSeedSubscriber实例,它包含了BlockingMonoSubscriber, 初始值和f。ReduceSeedSubscriber将累计数据的值设置为初始值。MonoReduceSeed调用FluxArray.subscribe(ReduceSeedSubscriber)订阅FluxArray。FluxArray创建Subscription实例。FluxArray调用ReduceSeedSubscriber.onSubscribe(Subscription)来通知ReduceSeedSubscriber订阅成功。ReduceSeedSubscriber调用BlockingMonoSubscriber.onSubscribe(ReduceSeedSubscriber)来通知BlockingMonoSubscriber订阅成功,这里ReduceSeedSubscriber既是一个Subscriber,也是一个Subscription。ReduceSeedSubscriber调用Subscription.request(unlimited)来请求数据,其大小为Long.MAX_VALUE,也就是无数量限制。BlockingMonoSubscriber调用ReduceSeedSubscriber.request(n)来请求固定大小的数据,该调用可发生多次。Subscription调用ReduceSeedSubscriber.onNext(value)来向ReduceSeedSubscriber发布数据,该调用可发生多次。- 当累计结果不存在时,忽略该数据,因为只有在取消后累计结果才可能不存在。
- 当累计结果存在时,
ReduceSeedSubscriber调用f(acuumulated value, value)来对计算新的累计结果。 - 在数据发布结束时,
Subscription需要调用ReduceSeedSubscriber.onComplete()来通知ReduceSeedSubscriber数据发布结束。 ReduceSeedSubscriber调用BlockingMonoSubscriber.onNext(accumulated value)来向BlockingMonoSubscriber发布累计数据。ReduceSeedSubscriber调用BlockingMonoSubscriber.onComplete()来通知BlockingMonoSubscriber数据发布结束。
总结
可以看到无初始值和有初始值场景的差别不大,是有可能复用同一个实现的。那为什么Project Reactor没有这样做呢?我们将在另一篇文章中进行讨论。

