引言
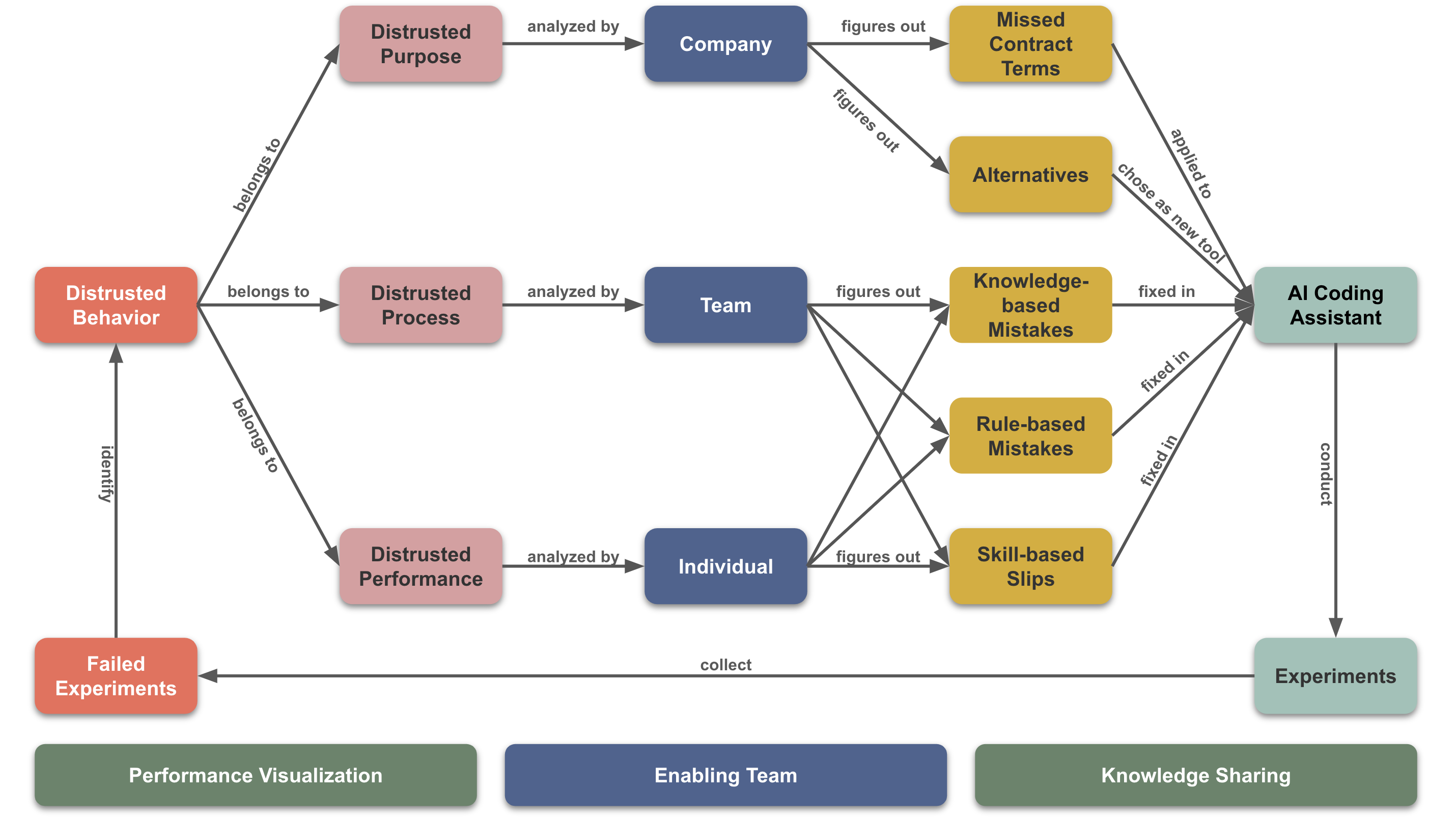
在文章《如何让团队真正接受AI编程助手?》中,我详细探讨了如何通过设计GitHub Copilot的系统指令来改善其行为,从而提升用户对其的信任度。最近,为了帮助孩子学习打字,我决定开发一个打字练习网站,以验证文章中提到的系统指令的实际效果。
结果展示
项目的源代码托管在https://github.com/sjmyuan/typing-practice,网站已经部署至https://typing.shangjiaming.com/。目前该网站支持以下功能:
自定义内容练习:用户可以输入任意文本进行打字练习。
唐诗三百首练习:内置经典唐诗内容,适合中文学习者。
多语言支持:练习内容可以是中文拼音或英文。

开发过程
在整个开发过程中我在GitHub Copilot的系统指令中主要添加了以下内容:
知识 (Knowledge):包括项目描述、技术栈、代码规范等基础信息。
技能 (Skills):如需求澄清、方案规划、测试驱动开发(TDD)等关键能力。
规则 (Rules):明确了开发流程中的具体要求,例如:
- 用户提交需求后,需先澄清需求,再规划方案,最后用TDD方式实现。
- 修改代码或测试后必须运行测试。
- 使用文件存储和获取命令行输出。
- 更新Storybook文档。
- 遵守开闭原则等。
所有代码均由GitHub Copilot生成,我仅负责提供必要的信息。典型的功能开发流程如下:
添加返回功能
添加全屏功能
在整个开发过程中,我提供的信息可以分为以下几类:
新功能需求:描述需要实现的新功能。
已有功能修改:说明对现有功能的调整需求。
Bug 描述:指出观察到的问题。
测试修复:描述测试失败的情况并让GitHub Copilot进行修复(通常是因为之前的会话未运行所有测试导致)。
测试结果反馈:提供测试结果或错误信息,尤其是在GitHub Copilot无法读取命令行输出时。
实现提示:在对GitHub Copilot的实现不满意时,提供可复用代码、已存在的类似功能或遗漏的代码等提示。
重构需求:针对生成的代码逻辑复杂或模块过大时提出重构建议。
其中,已有功能修改的需求最为常见。随着功能的增多,我发现前期准备的故事卡中缺失了许多细节,而我又不愿意花太多时间补充这些细节(主要是懒)。因此,在向GitHub Copilot提供信息时,我往往只能描述简单的细节,然后根据其生成的结果逐步提出修改需求,直到整体功能达到预期。
此外,在涉及全局性修改(如支持国际化)时,测试修复需求和实现提示出现的频率较高。这是因为GitHub Copilot倾向于聚焦于上下文,将修改集中在需求提及的几个模块,而忽略其他模块的测试,从而导致流水线无法通过。
开发体验
在开发过程中,Claude Sonnet 4 给我的体验最佳。它能够很好地理解和执行我设置的系统指令。
有时,GitHub Copilot + Claude Sonnet 4 会带来一些惊喜。例如,在修复 Bug 时,它会明确告诉我当前实现与期望行为是一致的,并指出我的 Bug 描述可能存在问题,随后提供两个方案让我确认哪个更符合预期。当它无法通过分析代码定位问题时,甚至会自动生成测试或添加日志来帮助定位原因。不过,这种操作有时会带来一个小麻烦:GitHub Copilot 偶尔会忘记清理之前用于调试的文件或代码。
最初,我会仔细审查生成的代码,尤其是测试代码。但随着开发的推进,我逐渐减少了对代码的审查频率,甚至有时无法完全理解生成的代码。我越来越习惯于只关注 GitHub Copilot 澄清的需求和生成的方案,并在需要时点击运行按钮。这或许就是所谓的 氛围编程 (Vibe Coding)。我不确定这种模式是好是坏,但在以下情况下,我可能会更加谨慎:
代码会被其他人审查:在这种情况下,我会确保自己能够理解所有代码,并保证其符合团队的最佳实践。
代码会被其他人测试:此时,我会至少仔细审查测试用例,以确保其验证的行为正确无误。同时,我会在向 GitHub Copilot 提交任务时提供更多细节。
有时间限制的任务:为了避免与 GitHub Copilot 的交互浪费时间,我会直接修改其生成的代码,快速完成实现。
起初,我将架构文档和代码规范文档链接到了系统指令中,本以为可以提升生成代码的质量,但结果却适得其反:
分散注意力:大量的架构和代码规范信息分散了 GitHub Copilot 的注意力,导致其对系统指令的遵守和执行质量下降。
过时内容的影响:这些文档是在编码前准备的,随着代码的演进,部分内容已经过时。由于我没有及时更新文档,GitHub Copilot 会基于过时的内容生成错误的代码。我尝试让它在功能实现后帮我更新文档,但这似乎陷入了“鸡生蛋还是蛋生鸡”的循环,效果并不理想。
因此,在后期开发中,我移除了架构和代码规范的内容,仅在 GitHub Copilot 出现明显错误时添加必要的信息以避免类似问题再次发生。
此外,我还注意到一个有趣的现象:当测试用例失败时,GitHub Copilot 往往倾向于修改实现代码,而不是测试本身。这在 TDD(测试驱动开发)的原则下是合理的,因为我们确实应该根据测试来完善实现。然而,有时我需要通过修改测试来反映新的需求。例如,上一次会话中,GitHub Copilot 修改了实现代码,但遗漏了部分测试的更新。这时就需要特别说明要根据实现来修改测试,而不能仅仅报告某个测试用例失败。
总结
通过为 GitHub Copilot 配备高级模型并设计良好的系统指令,我们可以在一定程度上实现类似 Cursor 的 氛围编程 (Vibe Coding) 体验。这种模式能够生成满足我们约 60% 需求的软件,但要将质量提升到 95% 或更高,仅靠氛围编程可能无法达成。而决定成功的关键,往往在于那些能够将质量从 60% 提升到 95% 的细节。
例如,让 GitHub Copilot 生成一个功能正常的网页并不难,但如果要求它生成一个在像素级别完全符合设计规范的网页,则需要更复杂的指令描述,甚至可能超出其能力范围。毕竟,我们能否准确描述所有像素级别的需求尚且存疑,即便能够描述清楚,GitHub Copilot 又能在多大程度上理解和遵守这些要求呢?
在这个小项目中,我更多地感受到自己作为开发者不断接受 GitHub Copilot 按照它的标准生成的结果,而不是让它完全按照我的标准来生成代码。前者让我感到舒适:只需提供简单的线索,然后接受看起来差不多的结果即可。而后者却让我感到痛苦:需要提前设计好一切,拒绝不符合预期的结果,并反复提供反馈,甚至可能陷入反馈无效的循环。
然而,在实际项目中,我们遇到的大部分情况都需要 GitHub Copilot 按照我们的标准生成结果。因此,我们仍然需要基于 信任提升模型 不断优化其行为,逐步提升我们对它的信任程度。